In der vergangenen Woche hat der Bundesgerichtshof (BGH) ein einschneidendes Urteil gesprochen. Geklagt hatten die deutschen Zeitungsverleger schon durch drei Instanzen gegen sie Smartphone-App der ARD-Tagesschau. Das Angebot der Öffentlich-Rechtlichen und damit Gebührenfinanzierten sei zu „pressemäßig“ und würde damit die Wettbewerbschancen der privaten Zeitungsanbieter im schwierigen Onlinemarkt mindern, die nicht nur ihre eigenen Onlineangebote privat, z.B. über Werbung, finanzieren müssten, sondern auch darauf angewiesen seien, damit Geld zu verdienen.
Wie die „pressemäßige“ Ausschlachtung eines Themas durch die Redaktion ARD-Aktuell funktioniert, dafür ist der gegenwärtige Streik der Lokomotivführer ein gutes Beispiel. Neben der umfangreichen Berichterstattung in der 20 Uhr-Ausgabe der Tagesschau verweist Jens Riewa auf das umfangreiche Zusatzmaterial, das die Onlineredaktion tagesschau.de bereithält und das auch über die Smartphone-App verfügbar ist.
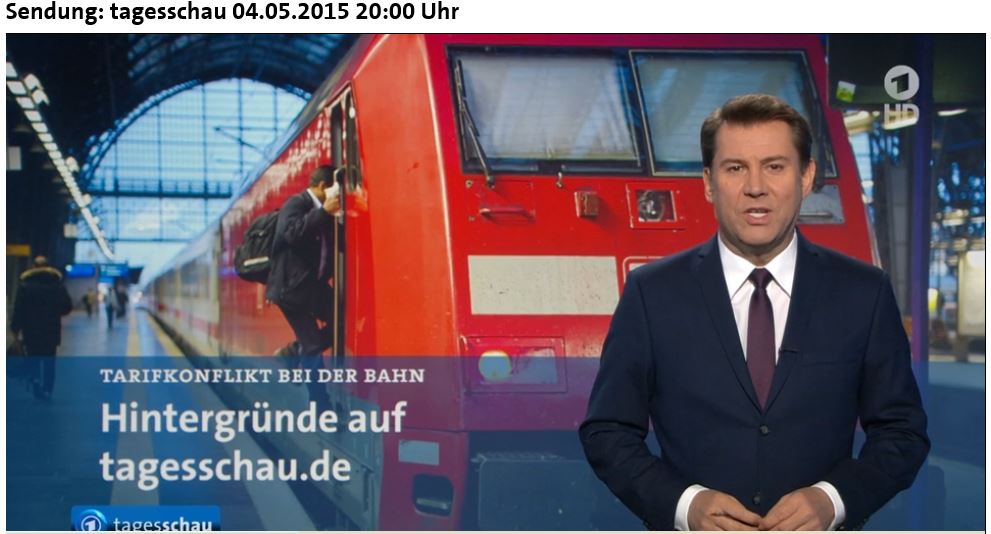
Aber wer, der mit dieser kräftigen Portion Eigenwerbung auf die öffentlich-rechtliche Website geht oder die Tagesschau-App benutzt, wird noch die ebenso umfangreichen Hintergrundinformationen auf sueddeutsche.de nutzen oder sich den Bahnstreik-Ticker auf welt.de zu Gemüte führen? Im Falle Google sind hochgradig strafbewehrte Verfahren bei der EU-Kommission anhängig, wie auch Tagesschau.de zu berichten weiß, weil der amerikanische Suchmaschinenbetreiber unter Umständen seine Marktmacht ausnutzt, um eigene Internetangebote durchzusetzen. Aber was macht die Tagesschau-Redaktion mit diesem offensichtlichen Stück Crosspromotion anderes, als die eigene Marktmacht im Fernsehen auszunutzen, um das hauseigene Internetangebot zu promoten? Da kann kein privater Zeitungs- und Onlineanbieter mithalten.